Measuring the Unmeasurable: How Complexodynamics Could Inform AI Evaluation Science

Here's a confession from someone who's spent many hours designing and analyzing AI evaluations for frontier models: we can be terrible at measuring how hard our tests actually are. Not just imprecise - fundamentally, philosophically terrible.
We often rely on gut feelings ("this seems hard"), post-hoc analysis ("models failed, so it must be complex"), or that most subjective metric of all - how long it takes a human expert to solve it. But the current gold standard - human expert time - varies wildly. Ask five experts to complete the same task and you'll get five different times, five different approaches, five different ways of making the model succeed or fail. Sure, you can take an average or a median but those metrics would still be subject to the same fundamental variability and subjective biases.
The Saturation Graveyard
The benchmark saturation problem is accelerating. Every few months, especially after 1-2 model releases (with time between releases accelerating in its own right), another benchmark joins what I call the "saturation graveyard." The pattern is predictable: researchers identify a capability gap, create a clever benchmark, celebrate the "robust" evaluation, watch models saturate it, discover the models found a shortcut we didn't anticipate. Repeat.
This is an open problem. Every saturated benchmark represents thousands of hours of expert time wasted. Organizations spend significant resources, sometimes millions of dollars creating evaluations that become obsolete almost immediately. A principled approach to complexity could help us invest more wisely.
What if our inability to create lasting benchmarks stems from this fundamental measurement problem? We need a measure of inherent task complexity that doesn't depend on who's doing the measuring or how they approach the problem. And what if a field called complexodynamics - traditionally used to study chaotic systems - could offer a way forward?
Complexodynamics: A Universal Language for Difficulty
Complexodynamics emerged from studying how complexity evolves in dynamical systems. While it's never been systematically applied to AI evaluation, its core principles might offer a starting point to what we need to start thinking of evals as a science: a mathematical framework for understanding task difficulty that doesn't depend on human intuition.
The field offers three potentially transformative tools:
1. Algorithmic Complexity: The Compression Test
One of complexodynamics' most elegant ideas is measuring complexity by compressibility. How short can you make a program that generates the solution? This gives us an objective, human-independent measure.
Consider image representation as an analogy:
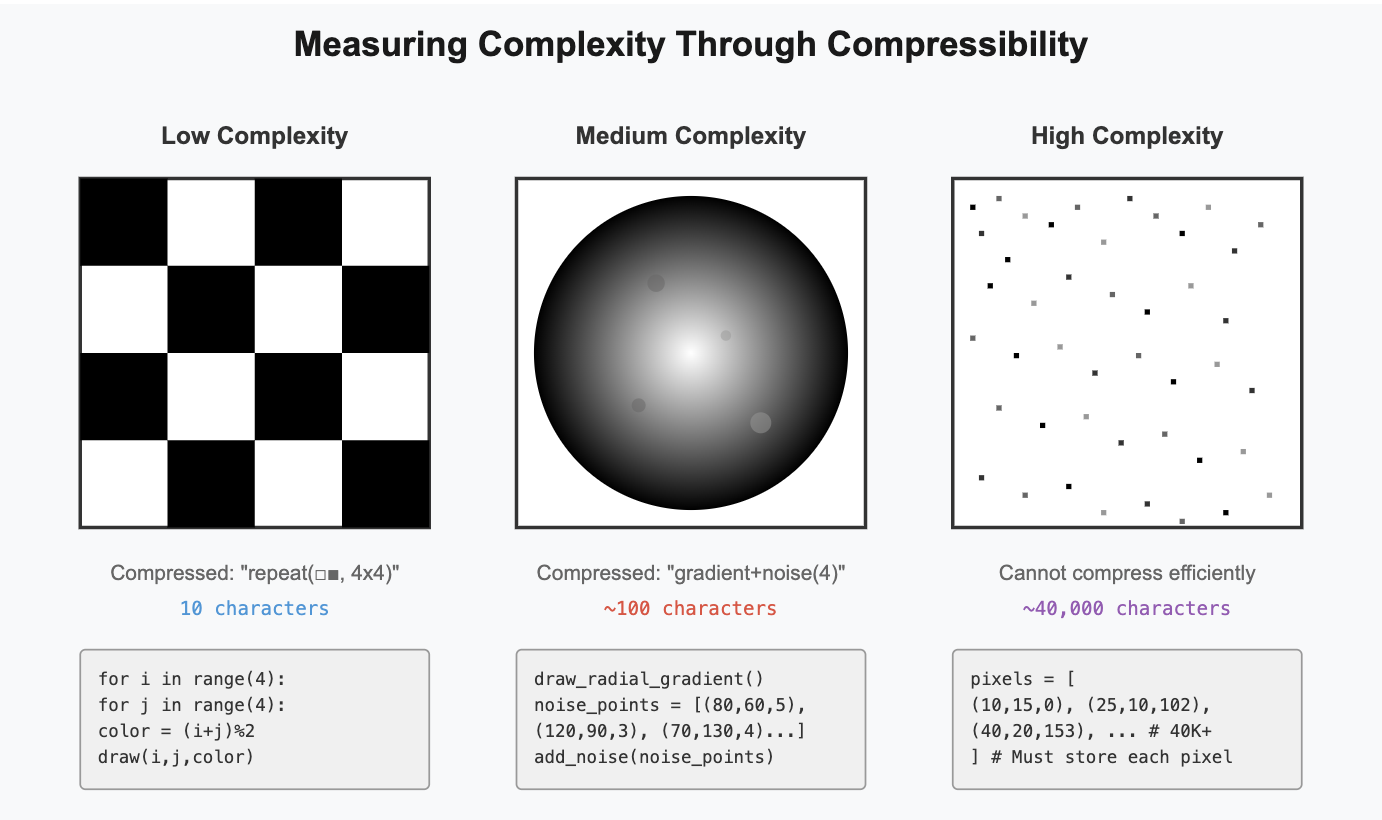
A checkerboard pattern compresses to a tiny program: "alternate black and white squares." Random static needs a program that specifies every single pixel – it's incompressible, hence maximally complex.
This translates directly to evaluation tasks:
- Low complexity: Tasks with simple, generalizable rules (basic arithmetic)
- Medium complexity: Tasks with patterns plus exceptions (natural language with idioms)
- High complexity: Tasks requiring extensive case-by-case specification (cultural context understanding)
2. Dynamic Evolution: Complexity That Grows
Static complexity measures miss something crucial: how difficulty changes as you engage with a problem. Complexodynamics tracks this evolution, revealing tasks that seem simple but harbor hidden depths.
Consider debugging: the initial error might be trivial, but fixing it reveals deeper architectural issues, which expose design flaws, which uncover fundamental misunderstandings. The complexity grows dynamically.
3. Resistance Patterns: Predicting What Models Can't Solve
Perhaps most valuably, complexodynamics could help predict which problems will resist even the most advanced models. Certain complexity signatures indicate fundamental barriers rather than just current limitations.
Identifying Saturation-Resistant Tasks and the Incompressibility Barrier
By analyzing tasks through a complexodynamics lens, we might identify characteristics that predict resistance to model improvements. Tasks that resist compression - that can't be reduced to elegant rules or patterns - will likely resist AI saturation. This isn't about current technical limitations; it's about fundamental complexity that can't be simplified away.
Examples of potentially incompressible tasks:
- Personal taste prediction: Each individual's preferences form a unique, irreducible pattern
- Cultural nuance navigation: Context shifts meaning in ways that defy systematic rules
- Creative breakthrough generation: True novelty can't be compressed into past patterns
A Potential Framework
If complexodynamics proves applicable to evaluation science, here's how it might work:
Complexity Vectors: Instead of single difficulty scores, we could think about how we might represent each task as a vector capturing different dimensions of complexity. Some potential examples:
- Algorithmic (minimum program length)
- Dynamic (how complexity evolves during solving)
- Structural (interdependencies between components)
- Interpretive (ambiguity handling requirements)
Evolution Tracking: Monitor how complexity changes as models engage with problems. Does the task reveal new layers of difficulty, or does it collapse to a simple pattern once the "trick" is found?
Compression Analysis: Measure how much information is truly required to solve a task versus how much is redundant. High compression ratios suggest pattern-matching suffices; low ratios indicate genuine complexity.
Challenges and the Path Forward
I want to be clear: applying complexodynamics to AI evaluation is a proposal, not a proven solution. The theory needs adaptation, the metrics need validation, and the whole framework might need substantial revision.
We'd still need to solve significant practical challenges. How do we compute these complexity scores efficiently for large benchmark suites? The computational cost of analyzing algorithmic complexity alone could be prohibitive. We'd need standardized methodologies - without consensus on measurement approaches, different teams would produce incomparable results. And perhaps most critically, how do we validate that our complexity metrics actually predict saturation resistance? We'd need extensive empirical testing across diverse benchmarks and model architectures.
But the potential is compelling as we think of new benchmarks and evaluate existing ones. Complexodynamics could potentially help inform:
- Predictive power: Identify which benchmarks will saturate next
- Forensic analysis: Study the "saturation graveyard" systematically - analyze why benchmarks failed, what shortcuts models found, and what complexity signatures might have predicted early saturation
- Efficient investment: Avoid wasting resources on evaluations that won't last
- Early warnings: Detect capability jumps before they surprise us
- Principled design: Create tests that probe specific types of reasoning
Building a benchmark for longevity
One thing I'd be excited about is applying complexodynamics in a way that could offer the creation of a systematic post-mortem process for saturated benchmarks. We're currently treating benchmark failures as isolated events, but what if these could be turned into valuable data points that could inform future design?
By analyzing complexity signatures of tests that fell quickly versus those that lasted, we could potentially build a predictive model of benchmark longevity. The saturation graveyard wouldn't just be a cemetery - it would be a dataset, giving us a consistent way to analyze and learn from these failures instead of viewing them as one-off events. I think there's a lot of potential for doing this for more deterministic benchmarks like in math and coding.
The future of evaluation science
The science of evaluation, especially for frontier models, is still nascent and early. The next time someone claims their task is "AI-resistant," we (hopefully) should be able to do more than nod and hope based on subjective expert time. We could analyze its algorithmic complexity, track its dynamic evolution, measure its incompressibility, and make evidence-based predictions about its future.
In evaluation science, we've been navigating by intuition when we could be using mathematics. Complexodynamics and related ideas might offer that precision instrument - we just need to figure out how to use it.