Beyond ARC: Reimagining Abstract Reasoning Benchmarks for the Next Generation of AI

There's something deeply fascinating about watching AI models tackle abstract reasoning challenges. As someone who spent years immersed in the world of quantitative aptitude and abstract reasoning tests — crafting, solving, and analyzing them — I've observed with keen interest as benchmarks like ARC-AGI have become the latest frontier in AI evaluation[1]. But as models like OpenAI's o3 achieve breakthrough performance levels at record pace[2], we must ask: where do we go from here?
Table of Contents
- A Brief History
- The Evolution of Abstract Reasoning Assessments and AI Capabilities
- Drawing Inspiration from Quantitative Assessment History
- The Progressive Development of AI Capabilities
- The Three-Tier Challenge Framework
- Three Proposal Categories for New Evaluation Approaches
- Why This Matters Now
- The Next Evolution in AI Benchmarks
- References
A Brief History
In 2019, François Chollet created the Abstraction and Reasoning Corpus (ARC), a novel AI benchmark measuring general intelligence through abstract visual pattern recognition[1]. Despite major advancements in AI through 2024, ARC remains undefeated by SOTA (state-of-the-art) models, with a $1M prize still unclaimed as of writing[2].
Recently however, OpenAI's o3 scored a staggering 87.5% on this benchmark[3] — while simultaneously scoring 87.7% on PhD-level GPQA questions and reaching the 99.7th percentile in competitive programming[3].
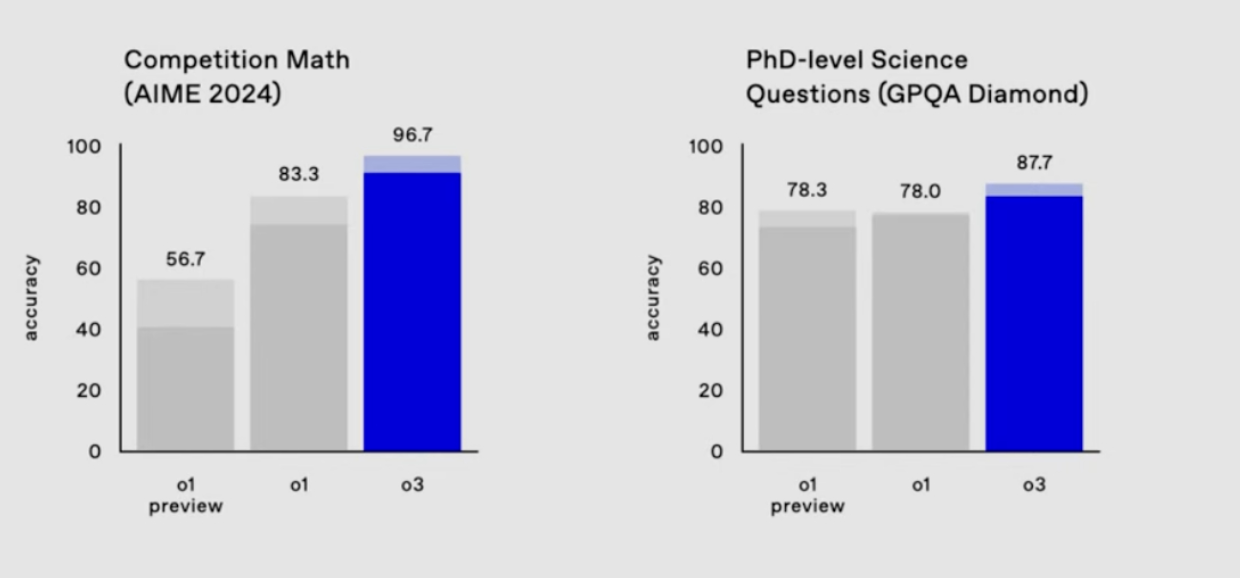
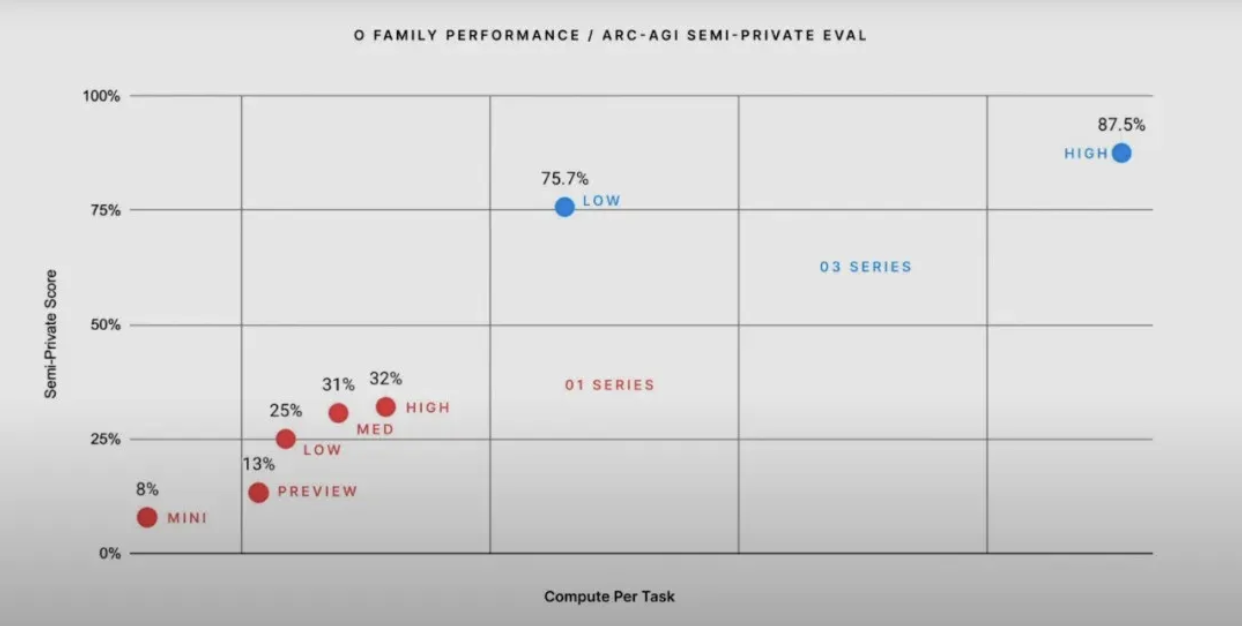
Contrast this to 2020, where GPT-3 scored 0% on the ARC-AGI benchmark[3]. Even in early 2024, GPT-4o scored just 5%[3] and bumped up performance to a score of 50% by mid-year[5].
Waves of competing SOTA models have emerged to continue challenging these benchmarks, and the AI development window continues to compress: the window for achieving 7th-grade-level performance spanned years, while reaching PhD-level mastery required only months.
The Evolution of Abstract Reasoning Assessments and AI Capabilities
Abstract reasoning assessments have deep roots in cognitive testing, drawing inspiration from established tools that measure problem-solving ability and critical thinking.
The parallel development of CCAT (Criteria Cognitive Aptitude Test)-style questions and ARC represents two distinct approaches to cognitive assessment. While CCAT was designed to differentiate human cognitive abilities through a variety of multi-modal challenges, ARC took a different path — creating problems that are intuitive for humans but challenging for AI systems[1].
CCAT-style questions are often used to screen candidates for quantitative roles, such as positions in quantitative finance. It evaluates cognitive ability across multiple dimensions: numerical, verbal, logical, spatial, and abstract reasoning[6]. The test consists of 50 questions to be completed in 15 minutes (approximately 18 seconds per question)[6]. Unlike ARC, which is designed to be easily solvable by humans, CCAT's abstract and spatial reasoning questions are intentionally designed to be moderately challenging for human test-takers.
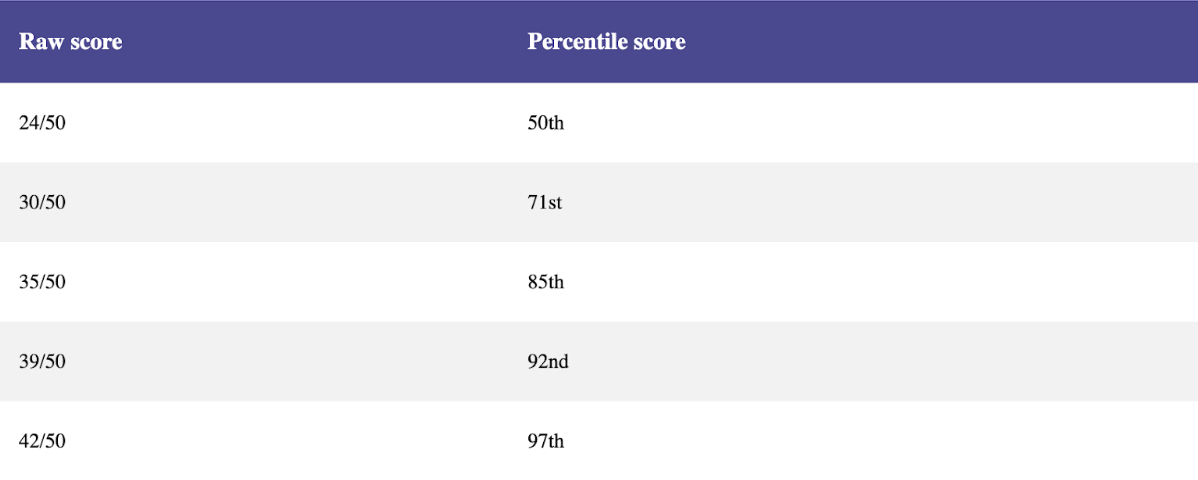
What's particularly intriguing is how quickly advanced AI systems are mastering certain types of benchmarks, while still struggling with seemingly simple reasoning tasks. For instance, in a 2023 study, GPT-4 was asked about Mable, who died at 11pm but had vital signs recorded at 9am and 7pm. When questioned if she was alive at noon, the AI responded that it was "impossible to definitively say" - despite this being trivial for humans[7]:

This reveals a crucial distinction in AI capabilities that François Chollet, the creator of the ARC-AGI benchmark, articulates: the difference between memorized skill and genuine intelligence[8]. Genuine intelligence, as Chollet defines it, is "the efficiency with which a learning system turns experience and priors into skill at previously unknown tasks"[1]. Current AI systems may achieve high performance through either unlimited prior knowledge or unlimited training data, but this differs from genuine intelligence which requires efficiently learning from minimal examples[1].
Consider the recent o3 results: while achieving an impressive 87.5% on ARC-AGI, analysis reveals this required massive compute resources and may rely heavily on sophisticated pattern matching rather than novel reasoning[9]. Novel reasoning, as Chollet emphasizes, requires "developer-aware generalization" - the ability to handle situations that neither the system nor its developer have encountered before[1]. This contrasts with systems that achieve high scores through extensive training on similar patterns or task-specific optimizations, which Chollet characterizes as "taking shortcuts available to satisfy the objective" rather than developing true generalizable intelligence[1].
The Progressive Development of AI Capabilities
Modern AI systems demonstrate a fascinating progression pattern in their capabilities: rather than exhibiting separate tracks for memorization and reasoning, they demonstrate a sequential learning progression. Like human learners, these systems excel at pattern recognition through repeated exposure before developing broader generalization abilities - a progression that becomes evident when examining their current strengths and challenges:
Areas of Strength (Pattern Recognition & Memorization)
- Professional domain knowledge (reaching 87.7% on PhD-level GPQA questions)
- Mathematical computation on familiar patterns
- Tasks with abundant training examples
- Problems that can be solved through pattern matching
Areas of Challenge (Novel Reasoning)
- Tasks requiring program synthesis from first principles[8]
- Problems with evolving or dynamic rules
- Scenarios demanding true causal understanding
- Transfer learning across drastically different contexts
Drawing Inspiration from Quantitative Assessment History
My experience with CCAT and similar assessments may offer valuable insights here. The most effective questions weren't necessarily the most complex—they were the ones that required novel combinations of reasoning patterns. This aligns with Chollet's "kaleidoscope hypothesis"—the idea that intelligence involves extracting and recombining fundamental patterns to solve novel problems[10].
The Three-Tier Challenge Framework
I propose we think about abstract reasoning benchmarks in three tiers of increasing sophistication:
1. Easy challenges for humans → Hard for AI (Current Benchmarks)
Where ARC-AGI sits today, though rapidly being mastered by advanced systems through sophisticated pattern matching and compute-intensive approaches[3]. This represents very simple reasoning for humans.
Examples in this category can include:
- Pattern completion where a simple rule like "rotate by 90 degrees" applies
- Identifying the next number in a sequence following a clear mathematical pattern
- Basic shape transformation tasks like "if circle then square, if square then triangle"
The upcoming ARC-AGI-2 benchmark, launching in 2025, will continue to focus on tasks that are easy for humans but challenging for AI[3].
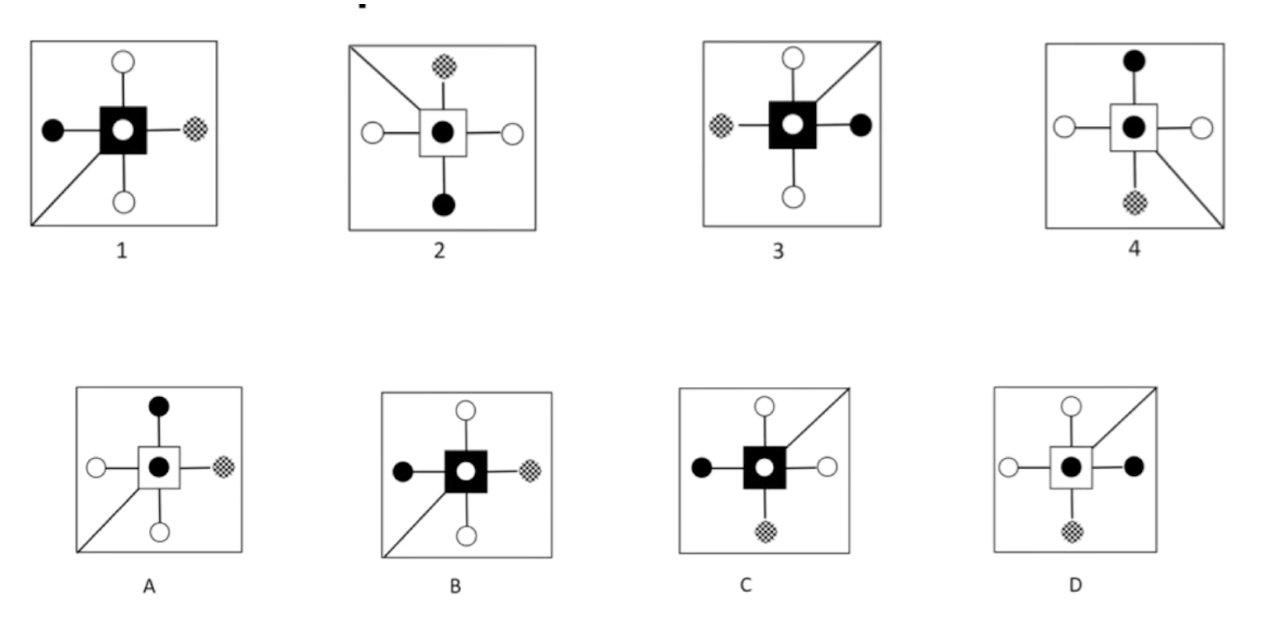
2. Moderate challenges for humans → Hard for AI (CCAT-Inspired Benchmarks)
Parts of traditional quantitative aptitude tests that challenge both human experts and AI systems, requiring sophisticated multi-modal reasoning.
Examples in this category can include:
- "Which shape doesn't belong?" problems where the underlying pattern requires multiple levels of abstraction
- Pattern anomaly detection where rules evolve during the sequence
- Problems where the rule itself must be inferred from a set of examples and then applied in a novel context
3. Difficult / nearly impossible challenges for humans → Even Harder for AI (Next Generation: Currently unsolved problems or recently solved "unsolved" problems)
Problems designed to probe true reasoning, incorporating Chollet's insights about program synthesis and abstraction.
Examples in this category can include:
- Unsolved problems: the Reimann hypothesis, P vs NP, the general problem of program synthesis from natural language specifications
- Recently solved "unsolved" problems: the Conway knot problem (solved in 2020), the Cap Set Problem (solved in 2016)
Note on levels: The gap between Level 2 and Level 3 problems is substantial. We could potentially define intermediate levels by analyzing:
- Population success rates across different problem types
- Solution times
- Cognitive load measurements
- Reasoning complexity metrics
This would provide a more granular assessment of abstract reasoning challenges. For comparison, consider EpochAI's Frontier Math benchmark, which features unpublished mathematical problems that challenge expert mathematicians for days[11].
Of course, what constitutes "Hard for AI" will evolve as AI capabilities advance.
Three Proposal Categories for New Evaluation Approaches
1. Dynamic Pattern Evolution
Instead of static pattern completion tasks, we can create problems where the underlying rules evolve as the solution progresses. This would test not just pattern recognition but the kind of program synthesis capability that Chollet identifies as crucial for genuine AI advancement[10].
Some ideas:
- A morphing geometric puzzle where rules change after each transformation (and gets more difficult as the model progresses)
- An evolving cryptographic cypher where the model must adapt its strategy and not simply memorize a fixed set of rules
- Puzzles that require non-linear transformations to be solved like fractal recursions
2. Contextual Rule Transfer
Develop problems that require applying learned patterns in radically different contexts, challenging the current limitations of transformer-based models in handling novel situations[10].
I'm still brainstorming examples of what this might look like in the context of a model benchmark. However, examples of this kind of transfer learning in humans could look like:
- Applying protein folding insights to a supply chain optimization problem
- Using game theory strategies from chess in business negotiations
- Translating computer vision techniques to audio processing
3. Abstract Anomaly Detection
Create sequences where the challenge isn't just completing the pattern but identifying subtle violations of established rules—probing the boundary between memorized patterns and true understanding.
An example:
- Code sequences where the anomaly isn't a syntax error but a subtle logical flaw that only manifests under specific edge cases or when considering program state over time
Why This Matters Now
The landscape of AI capabilities is evolving rapidly, as demonstrated by o3's breakthrough performance. However, this progress also reveals the limitations of current approaches[12]. As Chollet argues, we need to move beyond pure pattern matching and toward systems that can combine "type 1" intuitive pattern recognition with "type 2" explicit reasoning[10].
Increasing access to compute, accelerating high-quality data collection, and breakthroughs in algorithmic efficiency have created a compounding effect, driving several orders of magnitude of progress at an unprecedented pace. Inference costs plummeted by over 1000x in under two years[12].
Researchers didn't anticipate this speed of progress, as Jacob Steinhardt recalled during last month's Nobel Prize Hinton Lectures on a forecast he made in 2021: "(...) this prediction of 50% (on the math benchmark) in 2025 seems really wild to me."[13] That capability threshold, alongside many others, was quickly surpassed.
The Next Evolution in AI Benchmarks
The future of AI evaluation lies not just in making problems harder, but in creating benchmarks that specifically probe the boundary between pattern matching and true reasoning, and eventually, just true reasoning[13]. As o3's performance shows, we need tests that can distinguish between sophisticated pattern matching and genuine abstract reasoning capability.
We stand at a crucial juncture in AI development. While current models achieve impressive results through pattern matching and massive compute resources, the path to genuine artificial intelligence requires new approaches that combine deep learning with program synthesis. The next generation of benchmarks must help guide this development by clearly distinguishing between memorized skill and true reasoning ability.
References
- Chollet, F. (2019). The Abstract Reasoning Corpus (ARC): A Novel Benchmark for General AI. arXiv:1911.01547.
- ARC Prize. (2024). https://arcprize.org/
- Chollet, F. (2024, December 20). OpenAI o3 Breakthrough High Score on ARC-AGI-Pub. ARC Prize Blog. https://arcprize.org/blog/oai-o3-pub-breakthrough
- OpenAI. (2024). "OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12" [Video]. YouTube. https://www.youtube.com/watch?v=SKBG1sqdyIU
- Greenblatt, R. (2024, June 17). Getting 50% (SoTA) on ARC-AGI with GPT-4o. Redwood Research Blog. https://redwoodresearch.substack.com/p/getting-50-sota-on-arc-agi-with-gpt
- Criteria Corp. (2024). What to Expect on the Criteria Cognitive Aptitude Test (CCAT). https://www.criteriacorp.com/candidates/ccat-prep
- Arkoudas, K. (2023). GPT-4 Can't Reason. arXiv:2308.03762.
- Chollet, F. (2024). "The Difference Between Pattern Recognition and True Intelligence" [Conference presentation]. Stanford AI Safety Forum, Stanford, CA, United States. https://www.youtube.com/watch?v=s7_NlkBwdj8
- Chollet, F. [@fchollet]. (2024, December). "On o3's ARC performance: While impressive, the compute requirements suggest heavy reliance on pattern matching rather than true abstract reasoning." [Tweet]. X. https://x.com/fchollet/status/1870172872641261979
- Chollet, F. (2024). Pattern Recognition vs True Intelligence - Francois Chollet [Video]. YouTube. https://www.youtube.com/watch?v=JTU8Ha4Jyfc
- EPOCH AI. (2024). FrontierMath: A math benchmark testing the limits of AI. https://epoch.ai/frontiermath
- Situational Awareness. (2024). From GPT-4 to AGI: Counting the OOMs. https://situational-awareness.ai/from-gpt-4-to-agi/
- Steinhardt, J. (2024, February). AI RISING: Risk vs Reward – The Hinton Lectures™ (Day 1) [Video]. YouTube. https://www.youtube.com/watch?v=n1tmxAshOgE